
Ceph Storage is a robust, unified, petabyte-scale storage platform and fit for on-promises, public or private clouds.
Ceph Software
Defined Storage
Massively scalable unified distributed storage for
demanding applications.

Ceph Storage is a scalable, open, software-defined storage platform that combines the most stable version of the Ceph storage system with deployment utilities and support services. Ceph Storage is designed for cloud infrastructure and web-scale object storage. A Ceph Storage cluster is built from three or more Ceph nodes to provide scalability, fault-tolerance, and performance. Each node uses intelligent daemons that communicate with each other to:
• Store and retrieve data
• Replicate data
• Monitor and report on cluster health
• Redistribute data dynamically (remap and backfill)
• Ensure data integrity (scrubbing)
• Detect and recover from faults and failures
Ceph Storage provides effective enterprise block and object storage, supports archival, rich media,and cloud infrastructure workloads such as OpenStack and cloud-native for Kubernetes applications based.
Business problem and
business value
Business Value
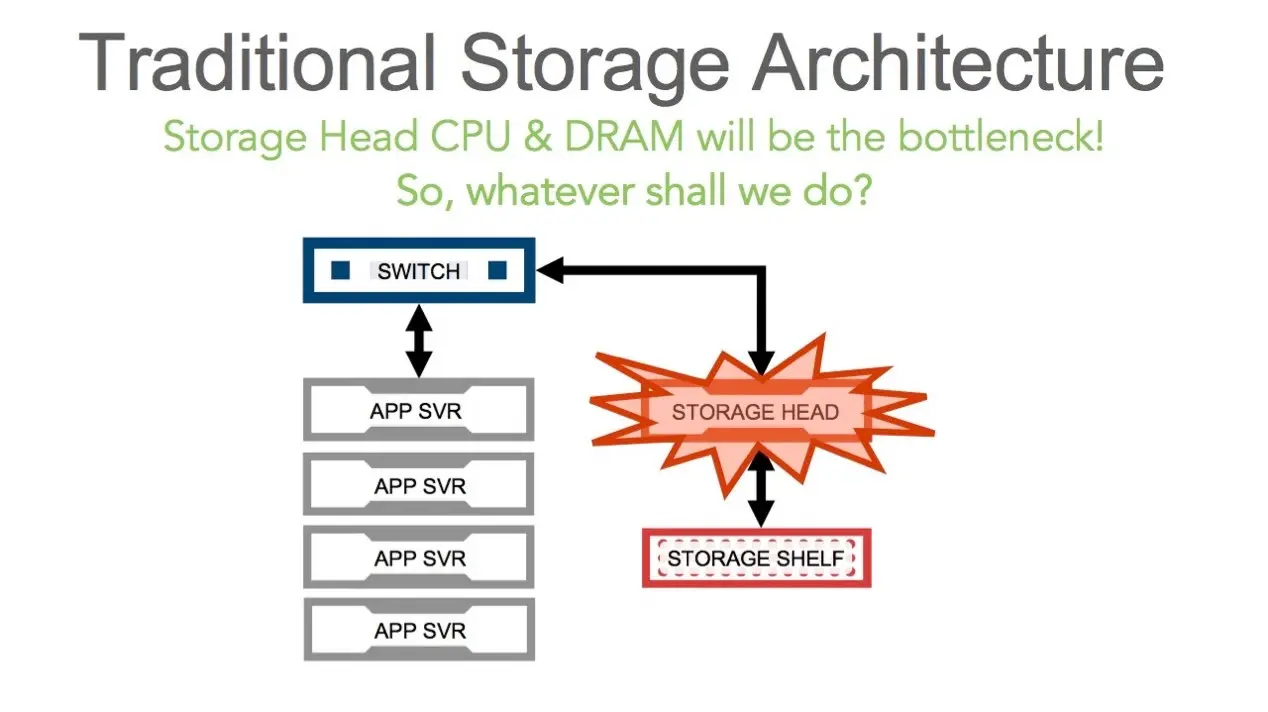
Traditional storage solutions have difficulties with petabyte level storage. Moreover, many traditional storage solutions do not exhibit high availability and have “single points of failure”.
For dealing with above problems, one storage solution, which can handle the following cases, is required.
• Be able to deal with petabyte level or even exabyte storage capacity
• Easy to scale out
• No single point of failure
• Cluster self-healing and self-managing

Business Value
Ceph Storage is a good solution to the business problem described above. Ceph is a unified, distributed, software defined storage system designed for excellent performance, reliability and scalability.
Ceph’s CRUSH algorithm liberates storage clusters from the scalability and performance limitations imposed by centralized data table mapping. It replicates and rebalances data within the cluster dynamically eliminating this tedious task for administrators, while delivering high-performance and excellent scalability.
The power of Ceph can transform organizations’ IT infrastructure and the ability to manage vast amounts of data. Ceph is mainly for organizations to run applications with different storage interfaces. Ceph’s foundation is the Reliable Autonomic Distributed Object Store (RADOS), which provides applications with object, block, and file system storage in a single unified storage cluster—making Ceph flexible, highly reliable and easy for management.

Block Storage
Ceph’s object storage system isn’t limited to native binding or RESTful APIs. You can mount Ceph as a thinly provisioned block device! When you write data to Ceph using a block device, Ceph automatically stripes and replicates the data across the cluster. Ceph’s RADOS Block Device (RBD) also integrates with Kernel Virtual Machines (KVMs), bringing Ceph’s virtually unlimited storage to KVMs running on your Ceph clients.
RBD offers a Ceph block storage device that mounts like a physi-cal storage drive for use by both physical and virtual systems (with a Linux® kernel driver, KVM/QEMU storage backend, or user-space libraries).

File System Storage
Ceph Provides a POSIX Compliant file system cephFS that aims for high performance, Large data storage and maximum compatibility with traditional and legacy applications. Ceph’s object storage system offers a significant feature compared to many object storage systems available today: Ceph provides a traditional file system interface with POSIX semantics. Object storage systems are a significant innovation, but they complement rather than replace traditional file systems. As storage requirements grow for legacy applications, organizations can configure their legacy applications to use the Ceph file system too! This means you can run one storage cluster for object, block and file-based data storage.

Object Storage
Ceph Object Gateway is an objeObject Storagect storage interface built on top of librados to provide applications with a RESTful gateway to Ceph Storage Clusters. Ceph Object Storage supports two interfaces:
- S3-compatible: Provides object storage functionality with an interface that is compatible with a large subset of the Amazon S3 RESTful API.
- Swift-compatible: Provides object storage functionality with an interface that is compatible with a large subset of the OpenStack Swift API.
Ceph Core Components
Ceph Storage is a robust, petabyte-scale storage platform and fit for on-premises, public or private clouds.
It is delivered in a unified self-healing and self-managing platform with no single point of failure,
and handles data management, so businesses and service providers can focus on improving application availability.
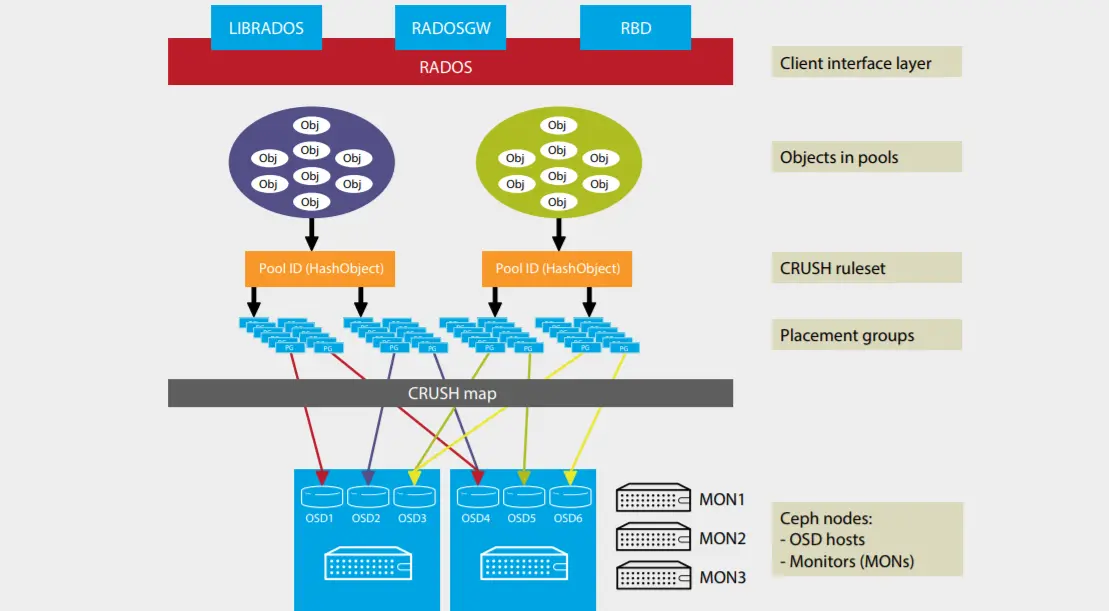
For a Ceph client, the storage cluster is simple. When a Ceph client reads or writes data (referred to as an I/O context), it connects to a logical storage pool in the Ceph cluster. The following sub sections illustrate the core components of Ceph cluster.
CRUSH ruleset
CRUSH is an algorithm that provides controlled, scalable, and decentralized placement of replicated or erasure-coded data within Ceph and determines how to store and retrieve data by computing data storage locations. CRUSH empowers Ceph clients to communicate with Object Storage Devices (OSDs) directly,
rather than through a centralized server or broker. By using an algorithm method of storing and retrieving data, Ceph avoids a single point of failure, performance bottlenecks, and a physical limit to scalability.
Pools
A Ceph storage cluster stores data objects in logical dynamic partitions called pools. Pools can be created for particular data types, such as for block devices, object gateways, or simply to separate user groups. The Ceph pool configuration dictates the number of object replicas and the number of placement groups (PGs) in
the pool. Ceph storage pools can be either replicated or erasure-coded as appropriate for the desired application and cost model. Erasure-coded pools (EC pool) is outside the scope of this document. Pools can also “take root” at any position in the CRUSH hierarchy allowing placement on groups of servers with differing performance characteristics—allowing storage to be optimized for different workloads.
Placement groups
Ceph maps objects to placement groups (PGs). PGs are shards or fragments of a logical object pool that are composed of a group of Ceph OSD daemons (see section 5.1.5) that are in a peering relationship. Placement groups provide a way of creating replication or erasure coding groups of coarser granularity than on a per object basis. A larger number of placement groups leads to better balancing.
Ceph monitors
Before Ceph clients can read or write data, they must contact a Ceph monitor (MON) to obtain the current cluster map. A Ceph storage cluster can operate with a single monitor, but this introduces a single point of failure. For added reliability and fault tolerance, Ceph supports an odd number of monitors in a quorum (typically three or five for small to mid-sized clusters). Consensus among various monitor instances ensures consistent knowledge about the state of the cluster.
Ceph OSD daemons
In a Ceph cluster, Ceph OSD daemons store data and handle data replication, recovery, backfilling, and rebalancing. They also provide some cluster state information to Ceph monitors by checking other Ceph OSD daemons with a heartbeat mechanism. By default, Ceph keeps three replicas of the data. A Ceph storage cluster configured to keep three replicas of every object requires a minimum of three Ceph OSD daemons, two of which need to be operational to successfully process write requests. Ceph OSD daemons roughly correspond to a file system on a hard disk drive. More OSD daemons improves performance but requires increased system memory, e.g. each OSD daemon needs at least 8GB memory.
Watch Ceph Tech Talk - What's New In Octopus Release
Ready to Discuss your Requirements?
Let us know what your business needs